


Dieses Jahr war in Bezug auf Neuerscheinungen aufregend, und das CityFALCON-Produkt nimmt mit Analysen, mehr Quellen und mehr Diensten, die in der ersten Hälfte des Jahres 2020 online gehen, wirklich Gestalt an. Viele der API-Dienste und -Funktionen sind in der Tat sehr leistungsfähig, und der F&E-Aufwand dahinter war beträchtlich. Aus diesem Grund haben die meisten neuen Funktionen ihre eigenen Blog-Posts, damit Sie sie besser verstehen können. Dieser Beitrag soll Ihnen lediglich vorstellen, was wir in diesem Jahr bisher erreicht haben.
Wenn Sie sehen möchten, was wir im ersten Halbjahr 2020 auf der Verbraucherseite getan haben, schauen Sie sich bitte die an CityFALCON 2020 Retail Updates Post.
Einreichungen von LSE, Companies House, Gazette und mehr
Ungefähr zu Beginn dieses Jahres haben wir damit begonnen, Einreichungen von der London Stock Exchange (LSE) und dem Companies House in Großbritannien zu bedienen. Seitdem haben wir The Gazette hinzugefügt, und wir sind dabei, Einreichungen von der SEC in den Vereinigten Staaten hinzuzufügen. Wir erhalten die Daten bereits und sind in unserer Staging-Umgebung eingerichtet, aber wir brauchen noch etwas Zeit, um die SEC-Einreichungen in die Produktionsumgebung zu übertragen.
Wir veröffentlichten eine vollständiger Blog-Beitrag zu unserer Veröffentlichung von Einreichungen. Derzeit sind sie nur über die API verfügbar, aber wir werden sie bald der Website und den mobilen Apps hinzufügen.
NLU-Extraktion
Ein weiteres sehr wertvolles Feature für Unternehmen ist unser NLU-Extraktionsservice. Auch dieser rechtfertigte es eigenen Blogbeitrag.
Wir haben den Dienst über einen Großteil der Lebensdauer von CityFALCON aufgebaut und wir haben ihn intern verwendet, um Entitäten aus Text zu extrahieren. Zum Beispiel extrahieren wir algorithmisch Amazonas aus einer Überschrift und markieren Sie es als Unternehmen für diesen Inhalt.
In Kombination mit unserer hierarchischen Datenbank können die resultierenden Informationen sehr aufschlussreich sein. Wir haben den Ticker von Amazon, ihre IRS- und SEC-Nummern und die damit verbundene Sektor-, Branchen- und Subbranchenstruktur.
Jetzt können Unternehmen diesen Service und strukturierte Daten für ihre eigenen internen Inhalte wie Memos, Chats, E-Mails und interne Berichte verwenden. Siehe den obigen Blogbeitrag für eine gründlichere Behandlung. Wir bieten die NLU-Entitätsextraktion als eigenständigen Dienst für die Indizierung interner Inhalte an, sodass abonnierende Unternehmen keine anderen API-Pakete erwerben müssen, wenn sie diese nicht benötigen.
Nachfolgend finden Sie ein Beispiel für die JSON-Antwort für eine einfache Nachricht, die zwischen zwei Mitarbeitern gesendet wird, was Unternehmen viele Einblicke bietet.
JSON-Antwort für informelle Nachricht zwischen zwei Mitarbeitern„Text“: „Sie denken, die USA werden Ermittlungen gegen Facebook einleiten“,
„lang“: „en“,
"Stichworte": [
{
„Start“: 14,
„Ende“: 16,
„Wert“: „USA“,
„Typ“: „Standort“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Vereinigte Staaten von Amerika“,
„Typ“: „geo_regionen“,
„Metadaten“: {
"Länder": [
"Vereinigte Staaten von Amerika"
],
„Subkontinente“: [
„Nordamerika“
],
„Kontinente“: [
"Nordamerika"
]
}
}
]
},
{
„Start“: 51,
„Ende“: 59,
„Wert“: „Facebook“,
„Typ“: „Firma“,
„matched“: wahr,
„Einheiten“: [
{
„Name“: „Facebook Inc“,
„Typ“: „Aktien“,
„Metadaten“: {
„legal_ids“: [
„0201665019_irs-uns“,
„0001326801_sec-us“
],
„Ticker“: [
„FB_US“
],
"Kategorien": [
"Sozialen Medien"
],
„Teilbranchen“: [
„Internetdienste & Infrastruktur“
],
„Branchen“: [
"IT-Service"
],
„Sektoren“: [
"Technologie",
„Kommunikation“
]
}
}
]
},
{
„Start“: 22,
„Ende“: 42,
„Wert“: „Untersuchung starten“,
„Typ“: „Ereignis“,
„übereinstimmend“: falsch
}
]
}
Ticker und gesetzliche Nummern, die vom NLU-Dienst gesammelt wurden, können in den Einreichungsdienst eingegeben werden, um viele Aufgaben zu automatisieren. Ein potenzielles internes Dashboard, das Entitäten extrahiert und dann in das Abrufen von Unterlagen, Recherchen und Nachrichteninhalten einfließt, könnte wie folgt aussehen:
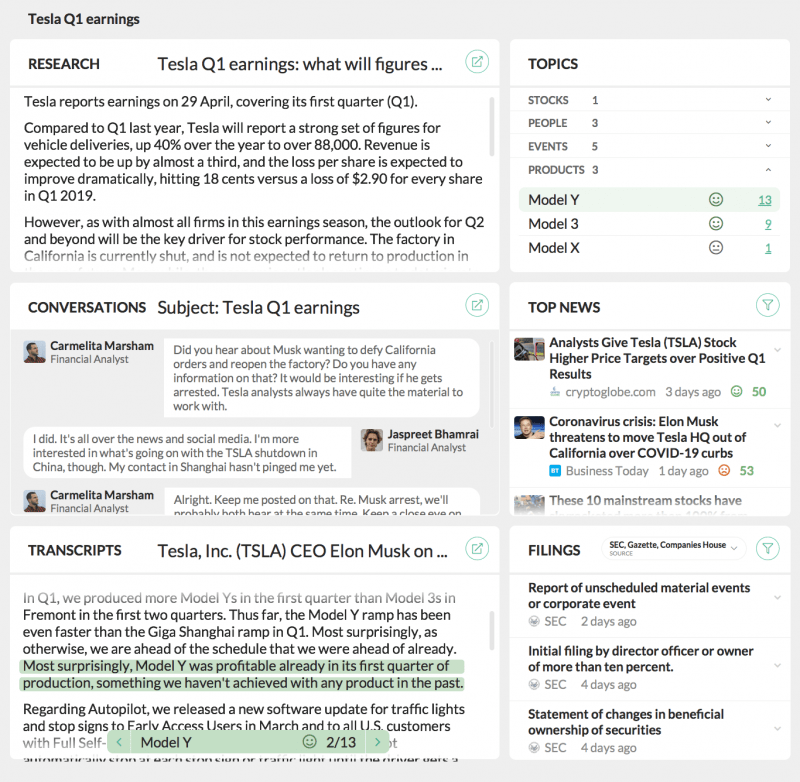
Eine potenzielle interne Anwendung, um Mitarbeiter bei ihrer Forschung und ihrem Betrieb zu unterstützen
Gruppierung ähnlicher Geschichten in 16 Sprachen
Similar Stories verwendet fortschrittliches, proprietäres maschinelles Lernen, um jeden einzelnen Inhalt, den wir erhalten, auf Ähnlichkeit zu vergleichen, einschließlich Nachrichten, Tweets und Berichte. Jeder Inhalt wird anhand von 512 Dimensionen wie Autor und Ort mit jedem anderen verglichen. Bei über 500 Dimensionen mögen einige natürlich wie seltsame Kombinationen erscheinen und für Menschen nicht viel bedeuten, aber die Korrelationen, die Big-Data-Algorithmen ziehen können, können einige subtile Ähnlichkeiten aufdecken.
Nachdem der gesamte Inhalt verglichen wurde, werden Gruppen basierend auf der Nähe zueinander im Ähnlichkeitsvergleichs-Vektorraum gebildet. Dann wählt die KI den repräsentativsten der Gruppe aus (die Schwerpunkt), und dieser Inhalt wird als Hauptstory markiert, die als Eintrag der obersten Ebene im JSON zurückgegeben wird. Innerhalb jedes JSON-Eintrags der obersten Ebene fallen die anderen Inhalte in der Gruppe unter die ähnlicher_inhalt Feld dieses Eintrags.
Im Web und auf Mobilgeräten ermöglicht dies Menschen, sich wiederholende Inhalte einfach zu überspringen oder umgekehrt verschiedene Einstellungen und Blickwinkel auf dasselbe Ereignis zu lesen.
In der API kann dieses Setup zu einer besseren Verarbeitung der verschiedenen Winkel führen. CityFALCON hat die Inhalte bereits gruppiert, sodass Ihr Unternehmen diese komplizierte NLU-Aufgabe nicht recherchieren und durchführen muss. Sie können sich jetzt darauf konzentrieren, Entscheidungen mit diesen ähnlichen Informationen zu treffen, anstatt Ressourcen zu binden, um zu versuchen, die NLU-Technologie aufzubauen – wir haben sie bereits für Sie entwickelt. Wenn Ihre Anwendung die Bereitstellung von Inhalten für Endbenutzer umfasst, können Sie alle ähnlichen Storys entfernen und nur die obersten JSON-Einträge (d. h. eindeutige Storys) anzeigen, sodass sie von der gleichen Verringerung der Redundanz profitieren.
Darüber hinaus funktioniert der Ähnlichkeitsalgorithmus in 16 Sprachen. Ein Anwendungsfall wäre die Erfassung von Nuancen für zweisprachige Teams, um den Denkprozess und die möglichen Ergebnisse von Ereignissen zu analysieren und Einblicke in diese zu gewinnen, basierend darauf, wer was wann schreibt.
Stimmungsanalyse
Dies ist eine weitere Funktion, die so wertvoll ist, dass wir eine geschrieben haben gesamten Blogbeitrag zur Stimmungsanalyse.
Die Stimmungsanalyse ist eine leistungsstarke Analyse, die NLU nutzt, um Inhalte basierend darauf zu bewerten, wie positiv, negativ oder neutral ihre Sprache ist. Unsere Systeme schlüsseln den Inhalt auf Klauselebene auf, sodass selbst ein einzelner Satz mehr als eine zugeordnete Stimmungspunktzahl haben kann (eine für jede Klausel).
Darüber hinaus können wir durch die Verwendung unseres NLU-Entitätsextraktionsdienstes (natürlich intern) feststellen, welche unserer 300.000 Entitäten in unserer Datenbank mit dem betreffenden Inhalt verknüpft ist. Dann erstellen wir aggregierte Bewertungen für alle Standorte, Personen, Unternehmen, Aktien, Organisationen und andere Entitätstypen in der Datenbank.
Aggregierte Gruppen, wie z. B. Sektoren (eine Zusammenfassung aller beteiligten Unternehmen), erhalten ebenfalls ihre eigenen Punktzahlen. Die Ergebnisse für die aggregierten Gruppen sind gewichtete Durchschnittswerte. Während CityFALCON also zusammen mit Microsoft und IBM im Technologiesektor liegt, haben diese beiden im Allgemeinen viel mehr Gewicht als CityFALCON, weil sie so viel mehr Medienaufmerksamkeit erhalten.
Eine vereinfachte Systemübersicht kann wie folgt aussehen:
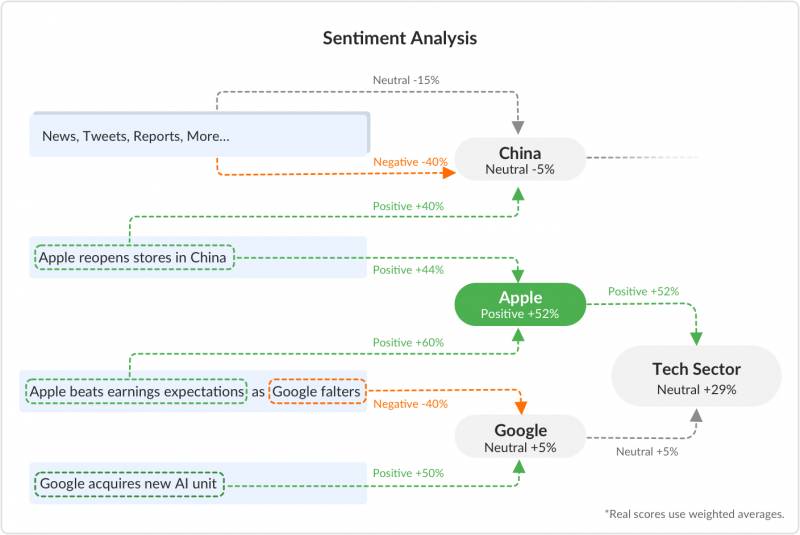
Eine vereinfachte Übersicht über Verbindungen zur Stimmungsanalyse
Über die API werden diese Daten zusammen mit Entitäten und Inhalten (Nachrichtenmeldungen) bereitgestellt. Eine schön formatierte (hübsch gedruckte) JSON-Antwort mit Sentiment könnte so aussehen:
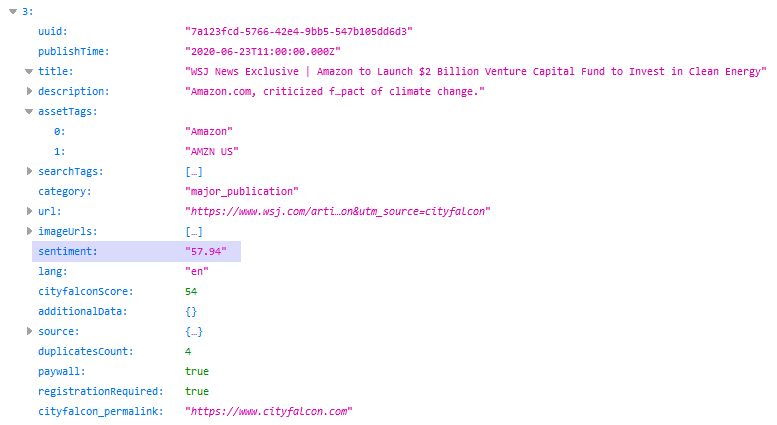
Hinzufügen des Legal ID-Felds für die Suche
Bisher hat die API nur akzeptiert Vermögenswerte, Ticker, und full_tickers als Eingabefelder, um Unternehmen, Personen und andere Ziele der angeforderten Informationen zu finden. Jetzt können API-Benutzer nach suchen legal_id, zu. Dadurch wird die Integration standardisierter und präziser. Darüber hinaus ist es einfacher, private Unternehmen anzusprechen, die keine Ticker haben. Zum Beispiel ist Revolut in Großbritannien ein sehr beliebtes Unternehmen, das man beobachten kann, aber es hat keinen Standardticker, um es zu identifizieren. Mit dem legal_id Feld, jetzt können API-Benutzer zielen 08804411_companieshouse-gb um Informationen über Revolut abzurufen.
Siehe die Wissensbasis für weitere Tutorials und Erklärungen oder schauen Sie sich die an Dokumentation um es im Sandkasten auszuprobieren.
Persönlicher API-Zugriff
Wir haben die API auch für den persönlichen Gebrauch geöffnet. Wir haben Interesse von Entwicklern und Einzelpersonen gesehen, die ihre eigenen Finanz- und Geschäftsanwendungen mit unseren Daten erstellen wollten, aber keine vollständigen API-Abonnements erwerben konnten.
Einzelpersonen können jetzt die API verwenden, um bis zu 10.000 Anrufe pro Monat zu tätigen und Story-Daten, den Titel, die Beschreibung und den CityFALCON-Score abzurufen.
Ein persönliches Abonnement beginnt bei $20 pro Monat für Benutzer aus dem akademischen Bereich, dem Gesundheitswesen und gemeinnützigen Organisationen oder $40 pro Monat für alle anderen. Bald kommt eine Premium-Version, die mehr Funktionen und ein höheres Anruflimit bietet.
Näheres steht in der dedizierter Blog-Beitrag zum persönlichen API-Zugriff.
Interessenten und die zweite Hälfte
Bisher haben wir in diesem Jahr einige wichtige Funktionen für die API veröffentlicht, und wir sind zuversichtlich, dass unser Unternehmen in der Lage ist, in Zukunft weitere zu veröffentlichen. Wir sind stolz auf das, was wir bisher erreicht haben, und freuen uns, die Früchte jahrelanger Forschung und Entwicklung in den Bereichen Data Science, Infrastruktur und Kuration von Finanzdaten zu ernten.
Wir fügen ständig neue Inhaltsquellen hinzu und wir setzen unsere fort F&E-Projekt in Malta um unsere Sprachabdeckung zu erweitern, sowohl aus inhaltlicher Sicht als auch in Anwendungen für maschinelles Lernen. Weitere maschinelle Lerndienste für interne Daten sind in Sicht.
Wenn Sie an API-Diensten interessiert sind, tun Sie dies kontaktiere uns für eine Beratung und Vorführung. Je besser wir Ihren Anwendungsfall und Ihre Situation kennen, desto bessere Produkte können wir Ihnen anbieten.
Schreibe einen Kommentar