


This year has been exciting in terms of new releases, and the CityFALCON product is really taking shape with analytics, more sources, and more services coming online in the first half of 2020. Many of the API services and features are very powerful indeed, and the R&D effort behind them was considerable. For that reason, most of the new features have their own blog posts, so you can more thoroughly understand them. This post is simply to introduce you to what we have achieved so far this year.
If you would like to see what we’ve done on the consumer side in the first half of 2020, please check out the CityFALCON 2020 Retail Updates post.
Filings from LSE, Companies House, Gazette, and More
Around the beginning of this year, we started serving filings from the London Stock Exchange (LSE) and Companies House in the UK. We have since added The Gazette, and we are about to add filings from the SEC in the United States. We already receive the data and are set up on our staging environment, but we need some more time to push SEC filings to the production environment.
We published a full blog post on our filings release. For now, they are only available through the API, but we will be adding them to the website and mobile apps soon.
NLU Extraction
Another very valuable feature for enterprises is our NLU extraction service. Again, this one warranted its own blog post.
We have built the service over much of the life of CityFALCON, and we were using it internally to extract entities from text. For example, we algorithmically extract Amazon from a headline and mark it as a company for that piece of content.
Combining this with our hierarchical database, the resulting information can be very enlightening. We have Amazon’s ticker, their IRS and SEC numbers, and their associated sector, industry, and subindustry structure.
Now, enterprises can use this service and structured data on their own internal content, such as memos, chats, emails, and internal reports. See the blog post above for a more thorough treatment. We provide NLU entity extraction as a standalone service for indexation of internal content, so subscribing enterprises have no need to purchase other API packages if they do not need them.
Below is an example of the JSON response for a simple message sent between two employees, which provides a lot of insight for companies.
JSON response for informal message between two employees“text”: “you think the US will launch investigation against Facebook”,
“lang”: “en”,
“tags”: [
{
“start”: 14,
“end”: 16,
“value”: “US”,
“type”: “location”,
“matched”: true,
“entities”: [
{
“name”: “United States of America”,
“type”: “geo_regions”,
“metadata”: {
“countries”: [
“United States of America”
],
“subcontinents”: [
“Northern America”
],
“continents”: [
“North America”
]
}
}
]
},
{
“start”: 51,
“end”: 59,
“value”: “Facebook”,
“type”: “company”,
“matched”: true,
“entities”: [
{
“name”: “Facebook Inc”,
“type”: “stocks”,
“metadata”: {
“legal_ids”: [
“0201665019_irs-us”,
“0001326801_sec-us”
],
“tickers”: [
“FB_US”
],
“categories”: [
“Social Media”
],
“subindustries”: [
“Internet Services & Infrastructure”
],
“industries”: [
“IT Services”
],
“sectors”: [
“Technology”,
“Communications”
]
}
}
]
},
{
“start”: 22,
“end”: 42,
“value”: “launch investigation”,
“type”: “event”,
“matched”: false
}
]
}
Tickers and legal numbers gleaned from the NLU service can be fed into the filings service to automate a lot of tasks. One potential internal dashboard that extracts entities then flows into retrieving filings, research, and news content may look like this:
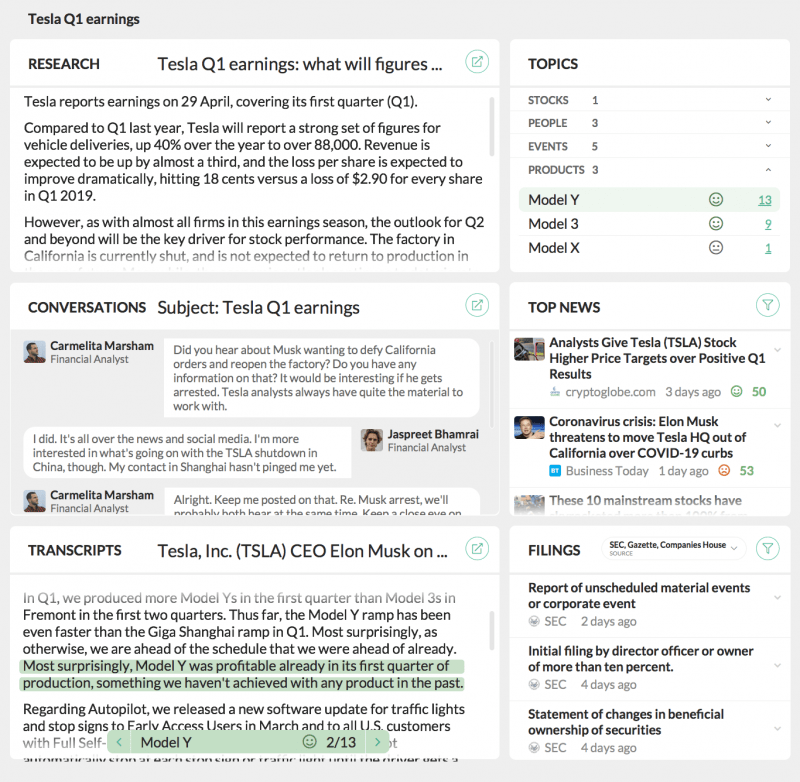
A potential internal application to assist employees in their research and operations
Similar Stories Grouping in 16 Languages
Similar Stories uses advanced, proprietary machine learning to compare each individual piece of content that we receive for similarity, including news stories, Tweets, and reports. Each piece of content is compared to every other piece using 512 dimensions, such as author and location. Of course, with over 500 dimensions, some may seem like odd combinations and may not mean much to humans, but the correlations Big Data algorithms can draw may uncover some subtle similarities.
After all the content is compared, groups are formed based on proximity to each other in the similarity comparison vector space. Then, AI chooses the most representative of the group (the centroid), and this piece of content is marked as the main story, which is returned as the top-level entry in the JSON. Within each top-level JSON entry, the other content in the group falls under the similar_content field of that entry.
On web and mobile, this allows humans to easily skip repetitive content or, conversely, read various takes and angles on the same event.
In the API, this setup can lead to better processing of the various angles. CityFALCON already grouped the content, so your company does not need to research and perform this complicated NLU task. You can now focus on making decisions with that similar information instead of tying up resources trying to build the NLU technology – we developed it for you already. If your application involves serving content to end users, you can remove all of the similar stories and only display the top JSON entries (i.e., unique stories), so they benefit from the same reduction in redundancy.
Moreover, the similarity algorithm works across 16 languages. One use case would be to capture nuance for bilingual teams to analyse and gain insight into the thought process and potential outcomes of events, based on who is writing what when.
Sentiment Analysis
This is another feature that is so valuable that we wrote an entire blog post on sentiment analysis.
Sentiment Analysis is a powerful analytic that leverages NLU to score content based on how positive, negative, or neutral its language is. Our systems break down content at the clause level, so even a single sentence can have more than one associated sentiment score (one for each clause).
Furthermore, by using our NLU entity extraction service (internally, of course), we can identify which one of our 300,000 entities in our database is associated with the content in question. Then we build aggregate scores for all of the locations, people, companies, stocks, organisations, and other entity types in the database.
Aggregate groups, such as Sectors (an aggregation of all constituent companies) also get their own scores. The scores for aggregate groups are weighted averages, so while CityFALCON is in the Tech Sector along with Microsoft and IBM, those two generally carry much more weight than CityFALCON because they garner so much more media attention.
A simplified overview of the system may look like this:
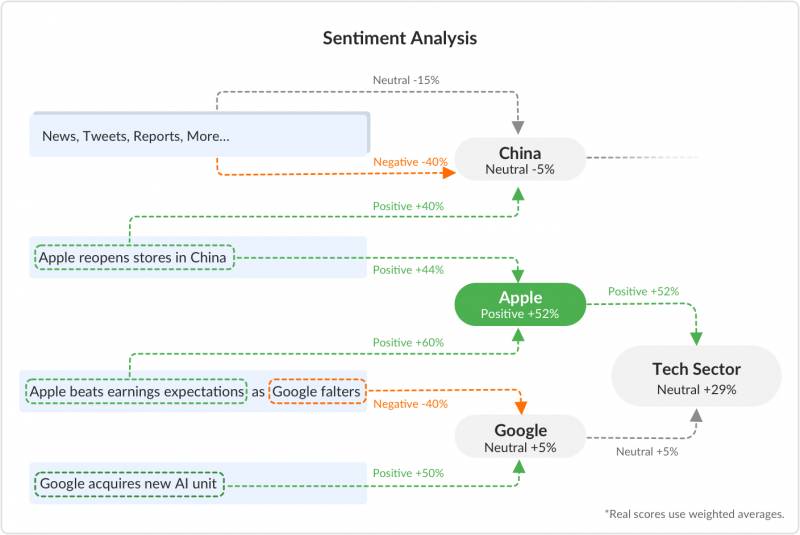
A simplified overview of sentiment analysis connections
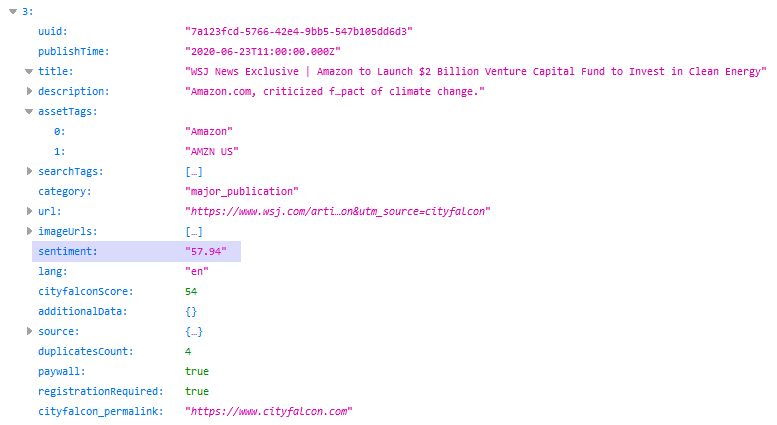
Through the API, this data is served along with entities and content (news stories). A nicely-formatted (pretty-printed) JSON response with sentiment may look like this:
Addition of Legal ID Field for Search
Previously the API only accepted assets, tickers, and full_tickers as input fields to find companies, people, and other targets of requested information. Now, API users can search by legal_id, too. This makes integration more standardised and precise. Moreover, it is easier to target private companies that do not have tickers. For example, Revolut in the UK is a very popular company to watch, but it has no standard ticker to identify it. With the legal_id field, now API users can target 08804411_companieshouse-gb to retrieve information on Revolut.
See the Knowledge Base for more tutorials and explanations or check out the documentation to give it a try in the sandbox.
Personal API Access
We have also opened the API for personal use. We saw interest from developers and individuals who wanted to build their own financial and business applications using our data but were unable to purchase full API subscriptions.
Individuals can now use the API to make up to 10,000 calls per month and retrieve story data, the title, description, and the CityFALCON score.
A personal subscription starts from $20 a month for academia, healthcare, and non-profit users or $40 a month for everyone else. A Premium version is coming soon that offers more features and a higher call limit.
More details are in the dedicated blog post on personal API access.
Interested Parties and the Second Half
So far this year we have released quite a few major features for the API, and we feel confident in our company’s position to release more in the future. We are proud of what we have accomplished to date and are ecstatic to reap the fruits of years of R&D in data science, infrastructure, and financial data curation.
We constantly add new content sources, and we are continuing our R&D project in Malta to expand our language coverage, both from a content standpoint and in machine learning applications. Additional machine learning services for internal data are on the horizon.
If you are interested in any API services, do contact us for a consultation and demonstration. The better we know your use case and situation, the better product we can provide you.
Leave a Reply