


Imagine the scenario: 75,000 documents and tons of news, research, and chat messages to sift, tag, and categorise with no discernible pattern in their sequence. You want to sort them by company and by location, but without the top-level, per-page, and per-sentence tags the task seems nigh impossible. Is the 14,198th document a macroeconomic report on North America, China, Tokyo, or the interplay of all three? Does the 47,938th document discuss dividends, earnings, or a new product launch? Does that client email from 6 months ago reference Google, Alphabet, or GOOG? Even worse, some sets of text may be hundreds of pages long and contain many different topics and pieces of important data. Titles, tables of contents, and top-level tags can only tell you so much.
You could hire people to read, understand, and organise every single document, email, news story, and chat message manually. Unfortunately, this consumes significant time and financial resources, and with chat logs, emails, news articles, and reports growing each day, it may be impossible to actually index all the content using human eyes and minds anyway. Messages between employees in one department could prove very useful for those in another, but most companies let this data disappear into employee inboxes, where its leverage potential is lost to the void.
A better solution is machine-learning-driven natural language understanding (NLU) systems, which automate the find, identify, and tag process, resulting in “tagged entities” or “extracted entities”. NLU is a broader approach to traditional natural language processing (NLP), attempting to understand variations in text as representing the same semantic information (meaning). With the entities extracted down to the sentence level, one can then perform all kinds of text analytics, like heat mapping and groupings that lead to insights. Sentiment analysis is another very popular textual analytic used for understanding large corpora (aggregated sets) of text.
At CityFALCON, we just launched an NLU entity extraction system and sentiment analysis tuned specifically for business, financial, and political content in multiple languages for identified entities and for entire documents, news stories, chat logs, and email chains.
The Need
There are several reasons to identify and tag products, companies, people, and other topics in text. One reason is that governments have document retention requirements, and some companies have very large sets of retained documents that are unorganised and unused for further Big Data analysis.
Other companies simply retain all of their messages and internal documents for future reference or for Big Data analysis later. If the text is internally-generated, perhaps they have a few tags on them, but they do not describe the content inside very deeply. If the text is externally-created, such as news content, tags may be insufficient, inaccurate, or nonexistent.
No matter the case, only a limited understanding of a text can be derived from top-level tags, titles of sections, and section summaries. Metadata exists through all the layers of a text, and NLU can help better understand single documents as well as a whole corpus. Since NLU works as granularly as the sentence level, documents can be algorithmically analysed by sentence and the output processed for powerful insight.
One of the promises of Big Data is to process quantities of information that single individual humans or teams of them simply could not. Because our human minds can only hold so much information in them at once, and communication between humans is limited by how fast we can transfer thoughts through language, understanding three million pages of news stories, documentation, and emails is not a feat for a human or even a team. It is for machines to distil into much more manageable bits.
NLU and associated analytics help companies organise their content, make it more quickly searchable with keywords, and can offer insights that human minds simply cannot synthesise (though we can understand the output, of course).
Thus, wherever there is a need to organise, categorise, and understand large volumes of textual information at high resolution, CityFALCON’s NLU system can provide insight and cross-department analysis with ease.
How It Works
At a high level, our newly launched API breaks down any set of text into its constituent sentences then identifies all the entities in each sentence. For example, let’s take a recent headline:
Stock futures fall after earnings, Trump’s threat for China tariffs over pandemic
Which our systems will split up like so:
Stocks = financial_instrument
Futures = financial_instrument
Earnings = event
Trump = person
China = location
Tariffs = financial_topic
Pandemic = financial_topic
And if you want to see the JSON response in full, we’ve posted it here for you.
{“text”: “Stock futures fall after earnings, Trump’s threat for China tariffs over pandemic”,
“lang”: “en”,
“tags”: [
{
“start”: 0,
“end”: 5,
“value”: “Stock”,
“type”: “financial_instrument”,
“matched”: true,
“entities”: [
{
“name”: “Stocks”,
“type”: “topic_classes”,
“metadata”: {}
}
]
},
{
“start”: 6,
“end”: 13,
“value”: “futures”,
“type”: “financial_instrument”,
“matched”: true,
“entities”: [
{
“name”: “Futures”,
“type”: “financial_topics”,
“metadata”: {}
}
]
},
{
“start”: 25,
“end”: 33,
“value”: “earnings”,
“type”: “event”,
“matched”: true,
“entities”: [
{
“name”: “Earnings”,
“type”: “major_business_and_related_activities”,
“metadata”: {}
}
]
},
{
“start”: 36,
“end”: 43,
“value”: “Trump”,
“type”: “person”,
“matched”: true,
“entities”: [
{
“name”: “Trump Family”,
“type”: “people”,
“metadata”: {}
}
]
},
{
“start”: 55,
“end”: 60,
“value”: “China”,
“type”: “location”,
“matched”: true,
“entities”: [
{
“name”: “China”,
“type”: “geo_regions”,
“metadata”: {
“countries”: [
“China”
],
“subcontinents”: [
“Eastern Asia”
],
“continents”: [
“Asia”
]
}
}
]
},
{
“start”: 61,
“end”: 68,
“value”: “tariffs”,
“type”: “financial_topic”,
“matched”: true,
“entities”: [
{
“name”: “Tariffs”,
“type”: “financial_topics”,
“metadata”: {}
}
]
},
{
“start”: 74,
“end”: 82,
“value”: “pandemic”,
“type”: “financial_topic”,
“matched”: true,
“entities”: [
{
“name”: “Pandemic”,
“type”: “other_topics”,
“metadata”: {}
}
]
}
]
}
Further, take the entity China. Because it was “matched” in our database, it also has a hierarchy associated with it. This means the term China can now be returned when someone searches Eastern Asia or Asia, too, allowing for much better indexing of internal content.
In addition to hierarchies, matched entities may bundle multiple names together. One such example is the term “Coronavirus”, which will be matched in our systems to “COVID-19”, “covid19”, and “covid”, among many other related words and short phrases. This allows an employee to search a single term and receive any related items, even if a simple text search would fail, because simple-text-searching COVID19 will not return mentions of Coronavirus.
Let’s look at another example. This one could be a chat message between employees:
– You think the US will launch investigation against Facebook?
Again, here is the JSON returned by our systems.
{
“text”: “you think the US will launch investigation against Facebook”,
“lang”: “en”,
“tags”: [
{
“start”: 14,
“end”: 16,
“value”: “US”,
“type”: “location”,
“matched”: true,
“entities”: [
{
“name”: “United States of America”,
“type”: “geo_regions”,
“metadata”: {
“countries”: [
“United States of America”
],
“subcontinents”: [
“Northern America”
],
“continents”: [
“North America”
]
}
}
]
},
{
“start”: 51,
“end”: 59,
“value”: “Facebook”,
“type”: “company”,
“matched”: true,
“entities”: [
{
“name”: “Facebook Inc”,
“type”: “stocks”,
“metadata”: {
“legal_ids”: [
“0201665019_irs-us”,
“0001326801_sec-us”
],
“tickers”: [
“FB_US”
],
“categories”: [
“Social Media”
],
“subindustries”: [
“Internet Services & Infrastructure”
],
“industries”: [
“IT Services”
],
“sectors”: [
“Technology”,
“Communications”
]
}
}
]
},
{
“start”: 22,
“end”: 42,
“value”: “launch investigation”,
“type”: “event”,
“matched”: false
}
]
}
Here the “US” is a matched entity and also contains a hierarchy. The specific topic United States of America will be identifiable with “the US”, “United States”, and “America”, and it can be found when someone searches Northern America, too. So when an employee vaguely remembers the conversation thread about “America”, they will not be frustrated by the mismatch between their search term, “America”, and the actual term used, “US”. In a regular text search, the attempt to find the conversation might fail.
Companies are also part of a hierarchy in the economy, and searching IT Services will ensure “Facebook” is included in the results, too. Not only that, but because Facebook is a public company, its legal identity numbers, including its SEC identifier and ticker(s) by country, are returned. This could be connected to company filings or programmatically fed into another algorithm that retrieves SEC filings from CityFALCON or be used to cross-reference court cases in the US court system.
Finally, it might also be useful to pick out actions from any conversation or research report. The phrasing launch investigation was picked up by our machine-learning systems as an event. This data helps determine the theme of a text, and a good use case would be marking emails with their events. In this example, the event was not matched, but there are tens of thousands of events on CityFALCON that are matched in the same way locations and companies can be matched with associated data.
Since machines do not care if you have 1 or 100,000 sentences, this same process can be repeated indefinitely for any sized corpus. All of this will be processed in a few seconds with our algorithm processing it on a fast GPU.
The Scope of the CityFALCON System
We identify 20 custom entities groups and more than 300,000 “named entity” topics that are finance-specific, adding a deep layer of possible analysis for banks, governments, academia, and other users who need content analysis based on economic and finance terms, going beyond products by competitors like IBM or Microsoft, whose systems are designed for general content.
For example, a single topic covers the idea of “United States of America”, where the associated names, like “US”, “America”, and “USA” are all considered part of that one topic, as is the metadata (for locations this is the geographic hierarchy). All topics come with associated information and, if available, hierarchies and associated names. They range from locations to people to companies and products, and you can even browse them in our Directory if you want to see them all. Through the API you will be able to index your own content in the same way, and this ability is a huge reservoir of organising power.
With all of these topics and entities groups, NLU as a cognitive tool transforms search from an instrument that fortifies an idea already present in the mind to an instrument that builds ideas based on concepts. Instead of searching a specific document or email chain for Biotech, workers can search for sector tags. Perhaps another sector is commonly mentioned along with biotech, serving as an avenue of potential insight. Conversely, one might wish to find all price movements in an email chain or set of 15,000 news stories, regardless of the direction and specific vocabulary used (surge, spike, jump, skyrocket, shoot up, etc.).
At the time of publication of this blog post, CityFALCON systems are ready to accept English and Russian content. Ukrainian and Spanish will be accepted this summer, and other languages will be added as our systems are developed through our R&D project underway in Malta, which includes Mandarin, Japanese, Korean, German, French, Portuguese and others. Eventually, we’ll cover 90+ languages.
NLU for Internal Content
The core of CityFALCON is NLU: we collect, aggregate, and process financial news and content – understand the language of it – and deliver it to users in real-time. We add some analytics on top, like a relevance score, sentiment, and some other ideas under development.
This huge engine of understanding primarily financial and economic language works well for all the data we source ourselves. It will work just as well on client text data, be it proprietary research, economic reports, earnings call transcripts, or simple internal memos and emails.
Our proprietary NLU engine is ready for use by clients to index and organise their own content. The NLU engine has been refined by our team of financial and NLU analysts over the past three years on news articles, Tweets, and regulatory filings. Now that power can be applied to internal financial content you’d like to index.
A potential employee portal may display the following components.
External Content
We provide this content from our 5000+ sources and Twitter. We’ll send you news, tweets, financial statements and regulatory filings, a CityFALCON relevance score, external content NLU data, and sentiment analysis.
Internal Content
This comes from any client-supplied text, like internal correspondence, publications, and informal email between departments.
Inter-organisational Content
Some of the returned tags contain not only names but also important information like position in economic hierarchies, such as sectors and subindustries, plus legal information like company ID numbers and tickers. These can further empower your search or automate some processes, like bringing up the latest stock quote from an exchange for your traders.
Real-time chat
Employee conversations are tagged as they transpire, providing searchable insights like how frequently a team mentions a sector or a key person during a workweek. This enables decision-makers to uncover otherwise obscured but useful information. If everyone is chatting about X, then X might just be the next big move in the markets.
This also empowers employees to look through past chat threads and search by entity or entity group instead of a specific keyword, broadening the potential to make connections. For example, someone might want to know all instances of a specific coworker mentioning “financial_instrument” or “company”, regardless of the specifics.
Real-time chat could even drive a real-time news feed that adapts to the current topic of the conversation.
Visualisations
This component makes it possible to understand the structure and themes of a set of texts at a glance, whether they be email threads with clients, the week’s news, or meeting minutes. The layout and design will have to be implemented on the company side, but CityFALCON can provide structured NLU data as the foundation of this component.
Just one example of an ad-hoc analysis of the strength of a trend could be visualised in the strength of the words employed. If all the headlines are saying “drift down”, “struggle”, and “float lower”, you know the situation is not as bad as if they’re all saying “plunge”, “implode”, and “decimated”. By utilising CityFALCON NLU, this kind of on-the-fly analysis becomes as simple as looking at all the instances of a price_movement tag in a set of texts.
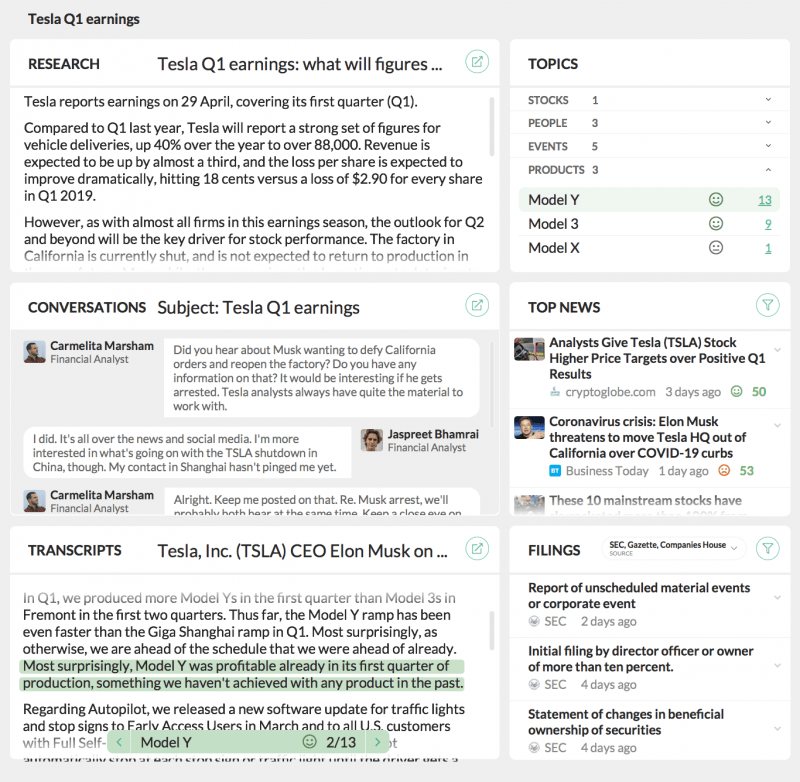
A potential employee dashboard of internal and external content
Why pay for the service?
Some may argue that building these systems themselves is easy or low-resource. Some may attempt to outsource tagging and organisation to cheap overseas labour, while others may try to hire a few developers to do it internally. None of these solutions adequately solves the problem though, and they miss out on a very important value addition.
First, the sheer volume of content may not be process-able by humans, so manual processing is not applicable. Additionally, it is not possible to apply manual NLU extraction to chats and other constantly changing sources in real-time. It is possible with machine learning and automated systems.
Second, these systems take a long time to build and implement. Not only do the algorithms need training, they need to be tested and adjusted. The entire system can take years to build up, while it is possible to license the technology right now.
Third, the underlying “understanding” and structure of the entire apparatus must adapt as new ideas and concepts come into the world. In business and politics, there are constantly new people, companies, laws, and events that must be tracked. You would need an entire team to track all of this and update the algorithms accordingly – fortunately, CityFALCON already does this for you with our multilingual financial analyst team.
Can these systems be built and maintained internally? Yes. However, their building and subsequent maintenance rapidly become expensive and time-consuming, especially in quickly-evolving areas such as finance, business, and politics. CityFALCON can handle the technical details. You focus on the customer and business.
Ultimately, value lies in data. With CityFALCON”s product, latent value can be extracted from financial and economic text sources and funnelled into revenue-generating endeavours like trading and portfolio management. We can help you enrich your metadata down to the words in sentences, connect individual entities to associated information, and build web-like connections between all parts of your business.
Security and Confidentiality
Since security and confidentiality are paramount when it comes to internal documentation or private correspondence between clients and employees, our system ensures your data is in safe hands.
Avoiding the technical details, all text you send will be sent through a normal HTTPS encrypted tunnel, so no one can read the request data you send. Then, on our servers, your data resides temporarily in RAM while it is processed. Once it is processed, all traces of your data disappear from our system. This means the text is never written to disk or stored on our database.
If someone hacks our systems or a rogue employee tries to sell client information, there’s no data to steal. Past content has been irretrievably erased. The only drawback is your request is not cached, so if you need to re-extract from the same set of text – perhaps it was accidentally deleted on an internal computer – you will need to retransmit it. However, the need to re-process a document is pretty rare.
Conversely, for those that really want to keep things local, we can offer a local-system deployment with regular updates, so the entire NLU process can occur at the client site, with data never leaving their own systems.
Convenient Integration
Using our API, any company can now index their internal content from past documentation or in real-time. It is as simple as querying the API endpoint for entity extraction (NLU tagging), and authorising yourself with your company’s unique key. Of course, you’ll need to build your own dashboard and interface for your own users, but we will handle all of the heavy lifting in NLU – this is the service we provide, after all.
Contact us to set up a demonstration and to discuss potential use cases, call limits, and any other questions you might have.
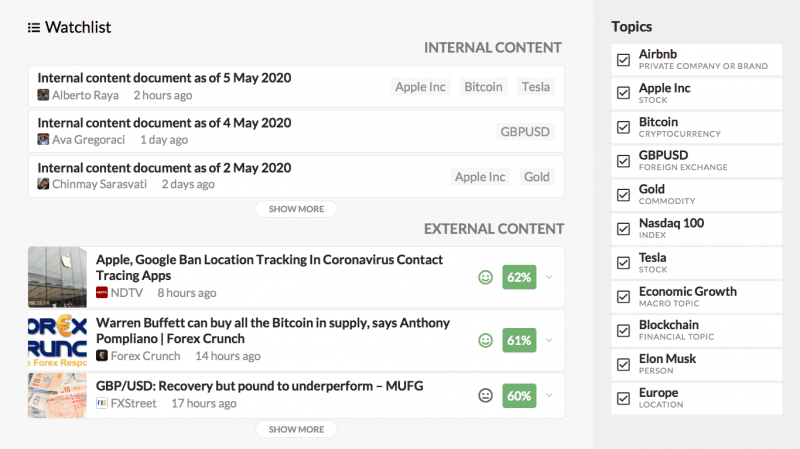
A simpler internal view with an associated watchlist
Leave a Reply